
- Total
꿈꾸는리버리
CreateML 도전기 본문
CreateML을 사용하기 위해 어떤 걸 해볼까 하다가
"사용자가 문장을 입력하면 어떤 감정을 느끼고 있었는지"를 예측하는 프로그램을 만들어 보기로 했다 !

이 중에 Text Classification 을 이용한 프로젝트가 될 것 같다 :)
우선 너무 무지한 상태였기 때문에 WWDC 영상을 먼저 확인했다. 영상을 보면 알겠지만, 이렇게 foldering을 해서 CreateML에 학습을 시켜야한다는 것을 확인했고, 각 폴더 안에는 해당 폴더에 해당하는 txt 파일들이 있다는 것을 알 수 있다.
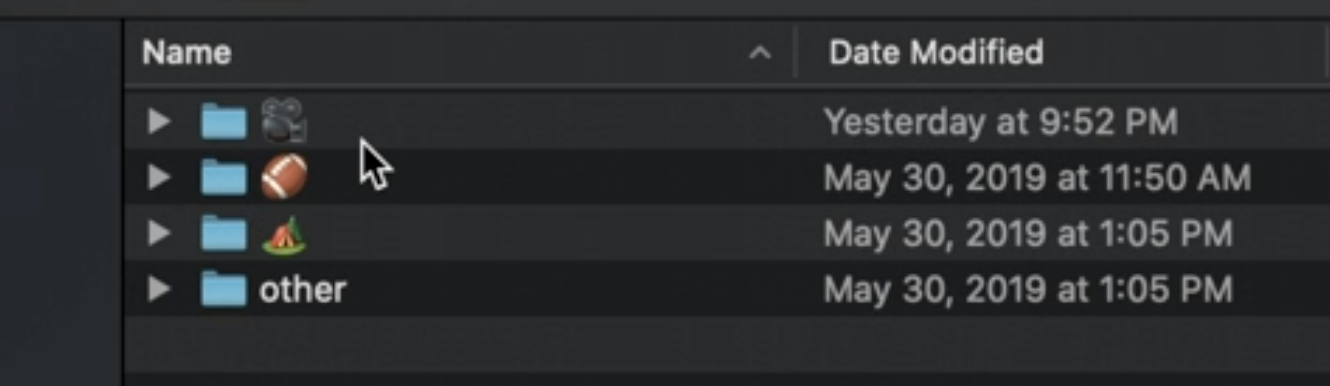
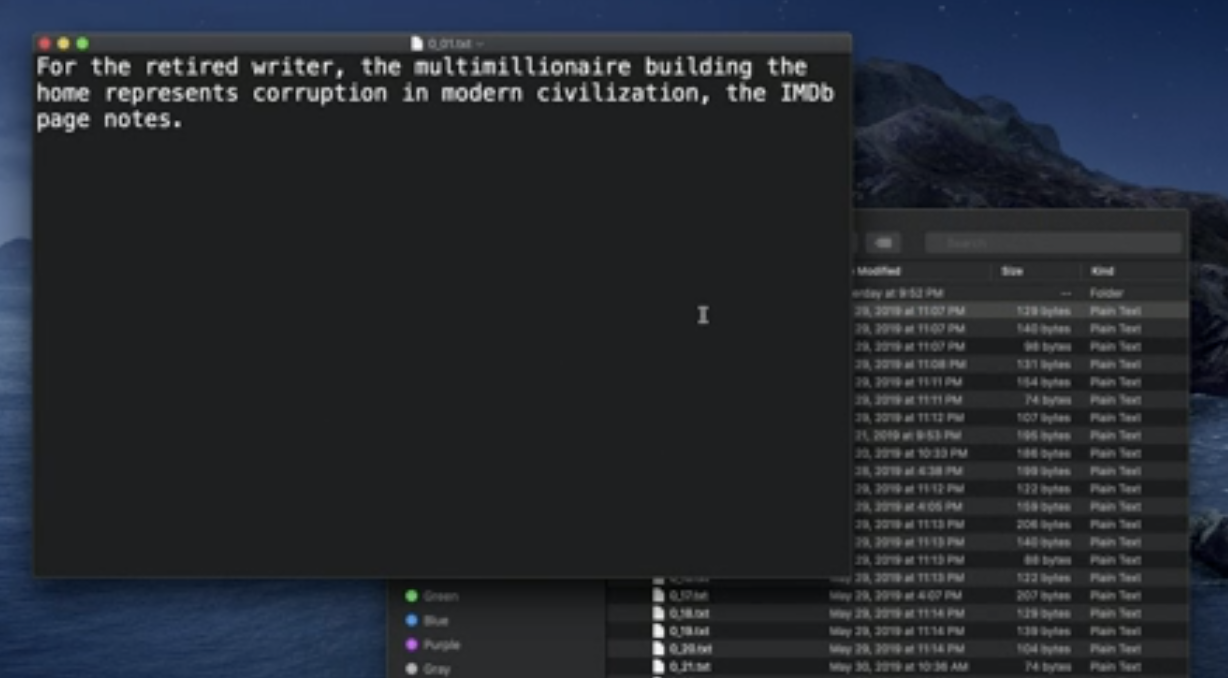
그렇다면.. emotion과 관련된 문장들이 필요하고, 그 문장들을 집합 시켜놓아야 하는데, CreateML의 예측도를 높이려면 그 양이 많아야 한다.... 이걸 다... 내가 치고 분류를 하면 평향성이 있을 것 같다는 생각이 들었고, 또 정보들을 수집하는 데에는 시간이 더 오래 걸릴 거라 생각을 했다. 그리고 처음에는 한국어로 text를 인식하려고 했는데, 한국어 data는 찾기 어려웠기도 하고 프로그램을 할때에도 한국어 자체에 제약이 많다는 정보를 찾아서 우선적으로는 영어를 도전해보기로 했다 !
이런 ML을 위한 정보를 제공하는 사이트들을 찾던 중 Kaggle이라는 사이트를 확인했다 !
다음 사이트에서는 ML을 위한 데이터들이 free로 많이 존재하기 때문에 찾기 좋았고, text 뿐만 아니라 다른 형태의 data도 확인할 수 있는 것 같았다. 좋은.. 사이트 인 듯하다...

회원가입을 끝내고 다운로드를 받으니 numbers로 해당 파일이 열였다. numbers에는 내가 원했던 data들이 정말 많았고... 정말 많았다..
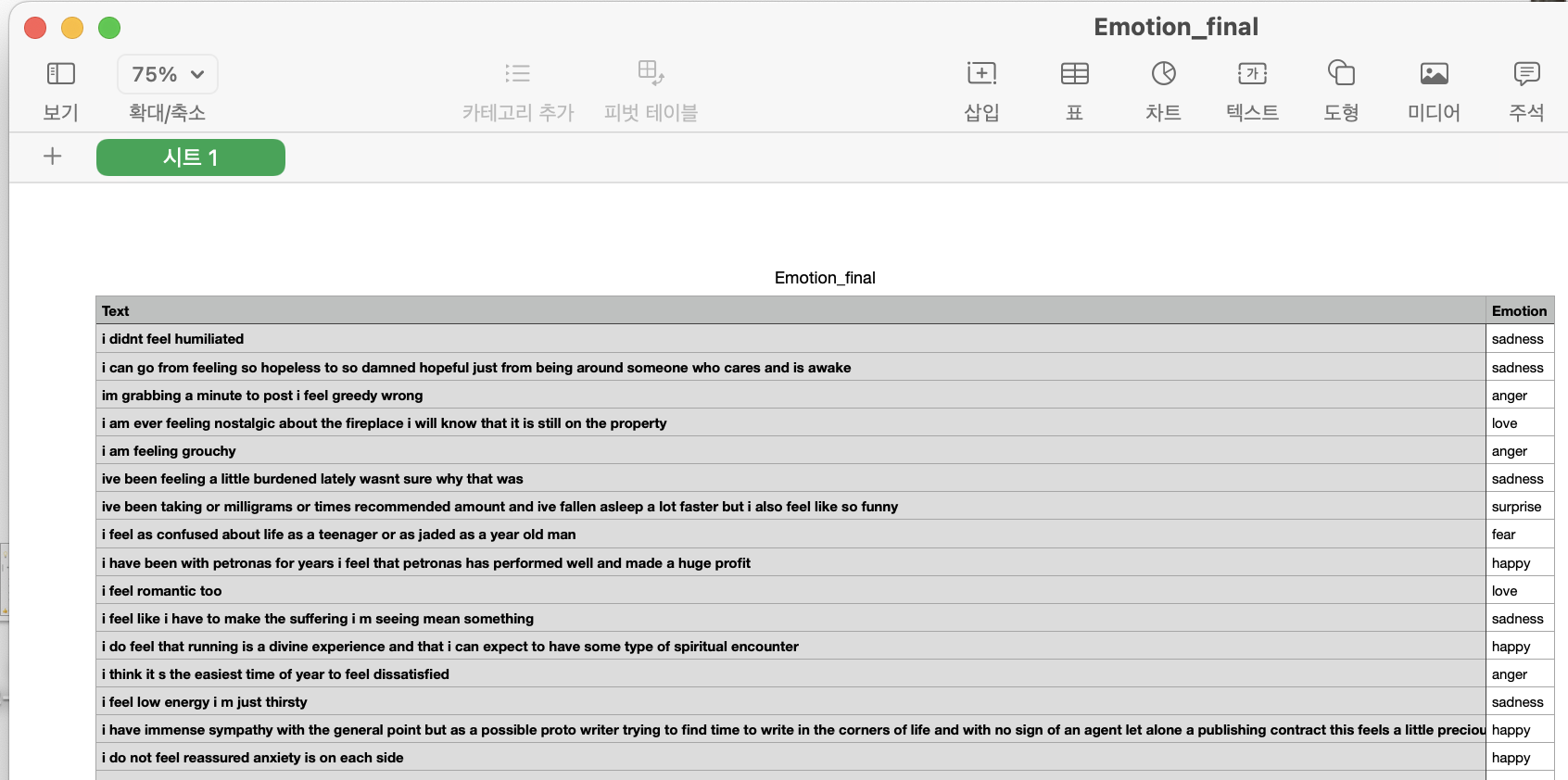
앞서 말한 것처럼 위의 사진처럼 문장들과 감정들이 연결되어져만 있으면 안되고,
아래의 사진과 같이 문장들은 txt로 존재하고 그 txt 파일들을 묶은 상위 폴더의 이름에 감정이 있어야 한다.

각 폴더 안에는 해당 폴더에 해당하는 txt 파일들이 있다는 것
그래서 이 데이터를 폴더링해야 했다.
이 부분은 해당 블로그에 자세한 내용을 담았다.
1. xcode에서 Create ML 열고 프로젝트 생성하기
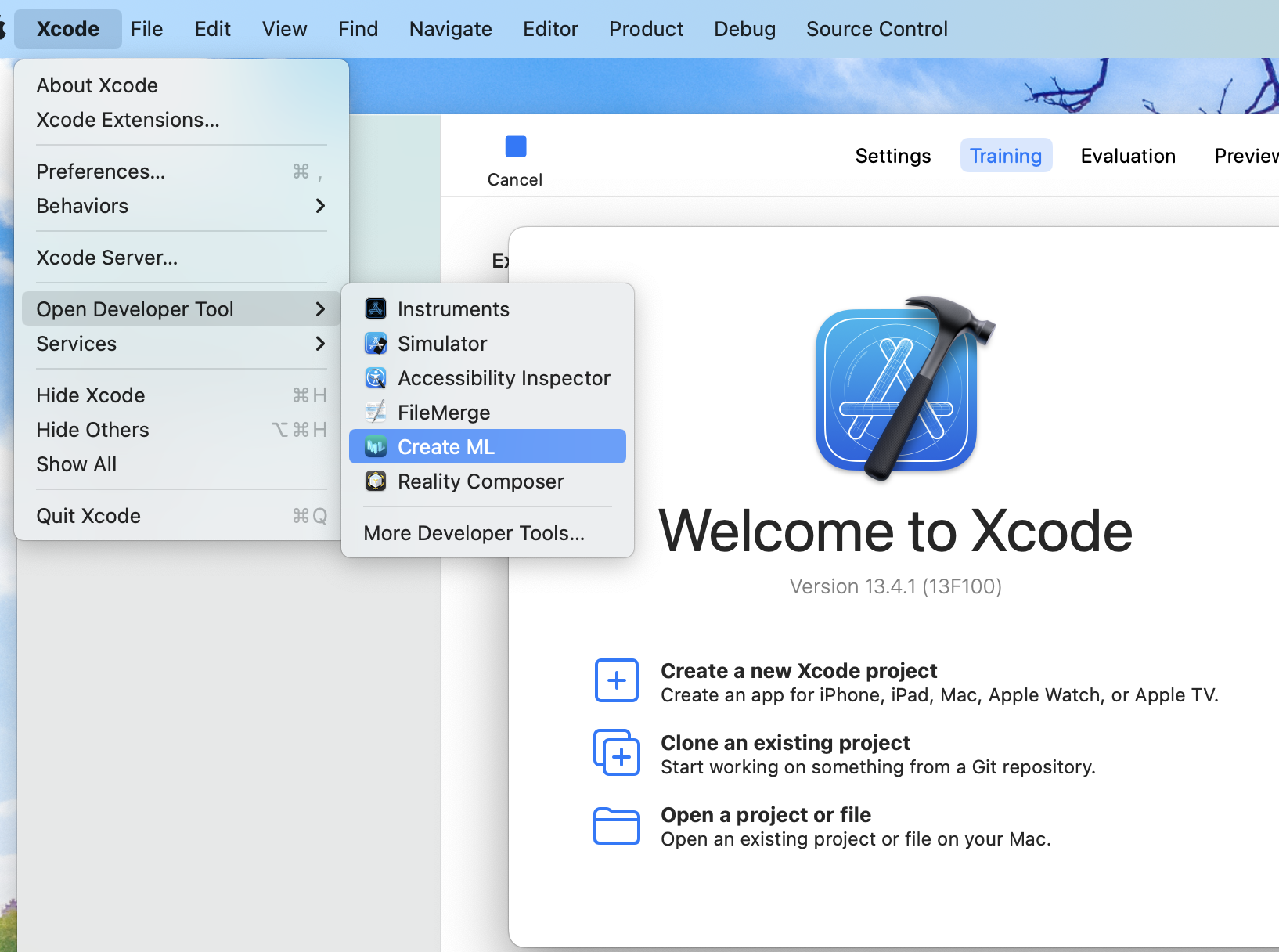

2. 학습 시킬 Emotion 폴더에서 이후 test를 하기 위해 몇 txt를 빼 두기

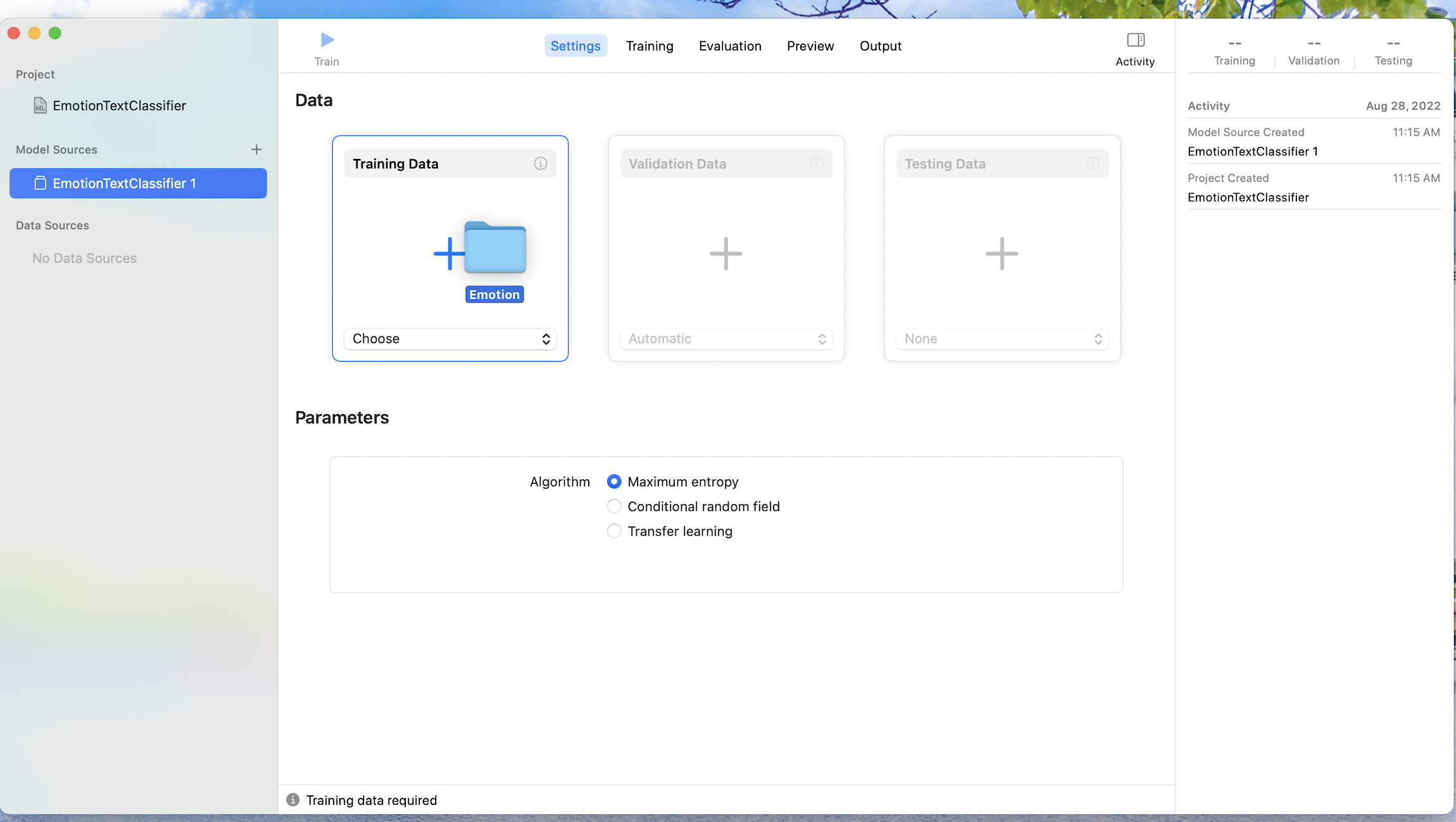
3. training Data에 Emotion 추가하기
4. 설정한 후에 좌측 상단에 play 누르기
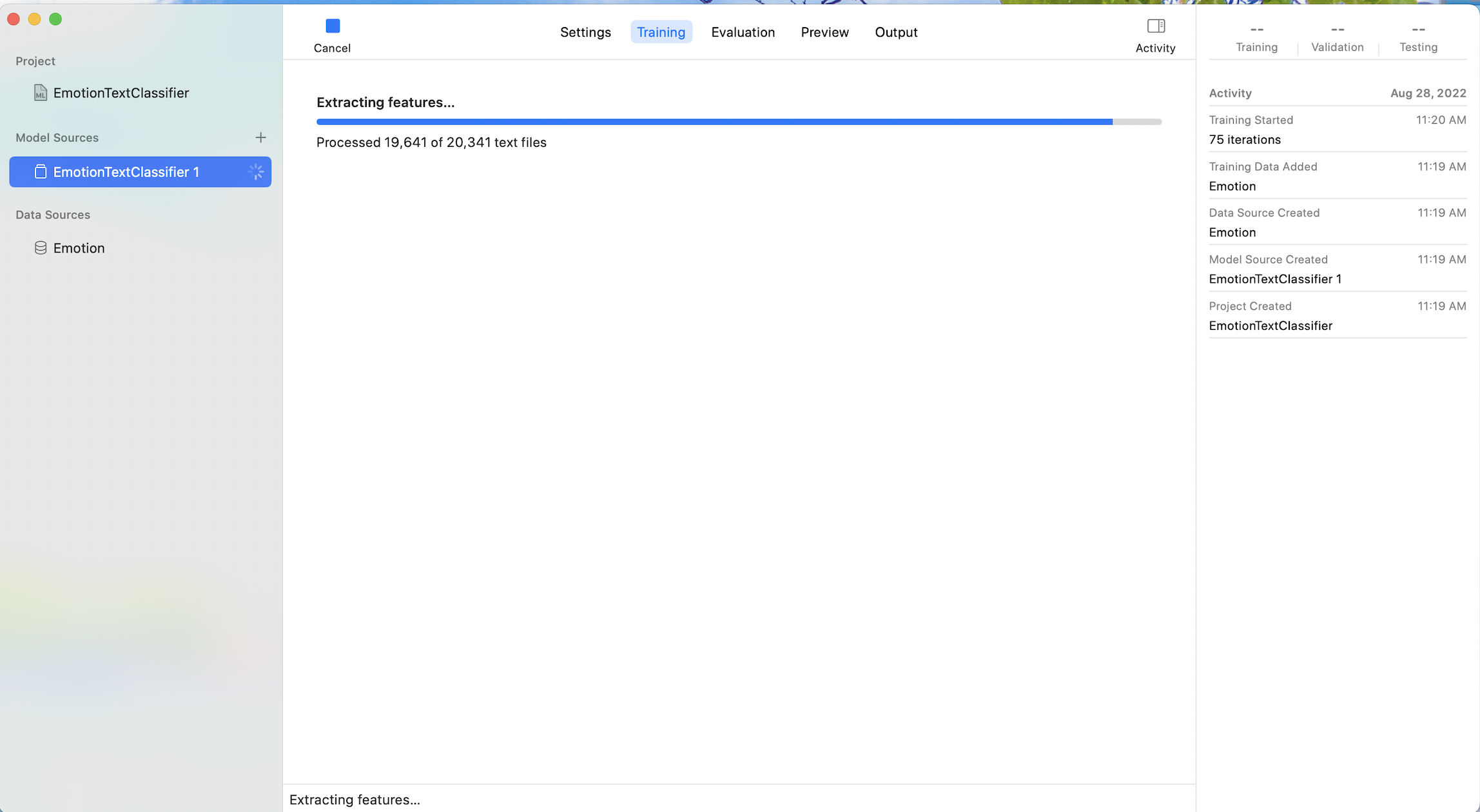

그리고 training이 다 될 때까지 기다린다.. ( 생각보다 오래 걸렸음 ... )
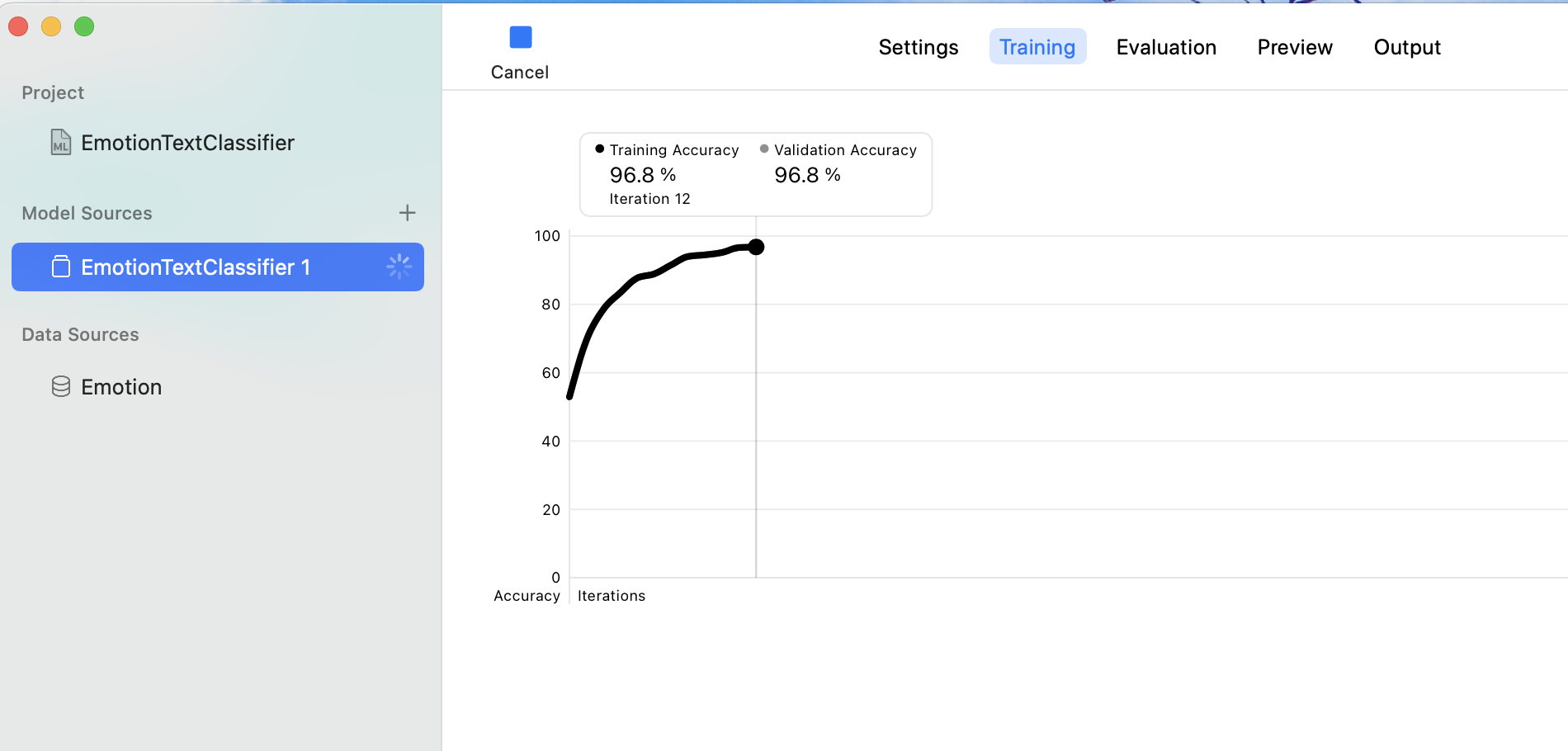
5. 확인해보면 어떤 확률로 결과가 적중하는 지 확인할 수 있다.

느낀점
생각보다 ML이 그렇게 어렵지 않아서 놀랐다. 만드는 것은 쉽지 않았지만, 데이터의 양이나 좋은 데이터를 모으는 일이 얼마나 어려운 일인지에 대해서 체감할 수 있었다. 사실 위의 예제에서도 실제 앱으로 돌려보니까 여러 문제점들이 있었다.
처음에 CreateML로 데이터를 만들었을 때는 100%와 가까운 confidence들이 나왔었다. 그래서 잘 된 줄 알았는데, 데이터의 편향이 심하게 있었다. 그 원인은 우선 데이터 양이 너무나도 차이가 났다는 점이었다. love의 경우는 몇 천 데이터였는데, happy는 몇 만 데이터가 있었다던가 그런..? 또 다른 원인은 테스트와 실제 넣었던 데이터의 비율이 고르지 않았다는 점이었다. 구글링해서 찾아보니까 테스트양 : 실데이터양 = 1: 9 or 2:8 정도가 되어야지 실제로 좋은 ML이 생성되었는지 확인할 수 있다고 했다. 이런 시행착오 끝에 위와 같은 정확도를 가진 ML을 다시 만들 수 있었다. 하지만, 위 규칙(?)들을 지키니까 정확도가 많이 낮게 나왔다. 그리고 일기에서 누군가의 감정을 판별하는 것이 좋은.. 일일까? 하는 고민에 빠지게되었다.
'오뚝이 개발자 > iOS' 카테고리의 다른 글
| 앱 공유하기 & 앱 스토어 리뷰 (앱 출시 전에 앱스토어 링크 찾기) (0) | 2022.09.12 |
|---|---|
| 협업할 때 Certificate & Provisioning Profiles (개념 + 실습) (0) | 2022.08.26 |
| AVFoundation, 음악 재생, MP3 (반복재생) (2) | 2022.08.11 |
| localization 다국어 타이핑 쉽게 하기 (excel을 이용한) (0) | 2022.08.07 |
| 엑셀 < - > json 변환 (0) | 2022.08.07 |



